There are a variety of known methods for 3D scanning of objects, which all have their different applications and trade-offs. Unfortunately, many of these methods require expensive camera arrays and mechanical equipment that is beyond the reach of those outside of very specialized research teams. The purpose of this project is to explore a low-budget, user-friendly system that can infer 3D models of objects by using information from photographs taken from a number of positions 360 degrees around the objects. The goal is to minimize user intervention and to automate the process as much as possible. This way, users who have little knowledge about computer vision can acquire 3D models using nothing more than an off-the-shelf digital camera such as a "flip video camera."
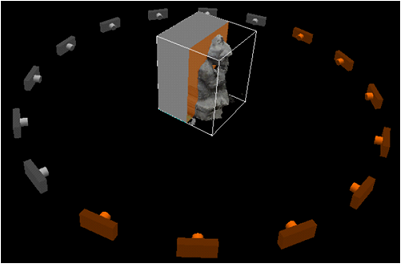
The main idea of this project is that circling an object from above by 360 degrees should provide enough viewpoints and information to reconstruct a 3D model. More specifically, this project starts with a 3D object mounted on top of a calibration target, in front of a black poster board (to minimize background noise, all explained in more detail later). A camera is mounted above the object looking down (so that the object and calibration target are always within view), a person walks around the object 360 degrees (keeping it within view), and video footage is taken. Our system splits the video into different frames and does reconstruction based on what is visible in each frame. Once the video has been acquired, there are three main steps in the pipeline: automatic 3D->2D point correspondence with known points on the calibration target, camera modeling and calibration, and voxel coloring. Each step will be explained in more detail in the body of this paper.
Past Work:
Voxel coloring and space carving are known techniques for 3D reconstruction in the computer vision community, as is camera calibration (there are a variety of nonlinear techinques more complicated than the model we chose to use). But many of them require complicated hardware setups. We found an assignment from the univeristy of Amsterdam that does something similar to what we're attempting to do using voxel coloring [3]. However, the camera calibration library that they are using requires more intervention than ours (a big focus of our project is automatic the calibration process as much as possible). Therefore, although our project does deal with known techniques and the purpose is mostly to explore feasability and implementation details with limited funds, we are combining different computer vision techniques in a novel way that should make the system more usable to the "common man."
The CImage Image Manipulation Library for C++ is used to do anything related to image processing, including edge and corner detection, camera calibration, and even user input (to help the corner detection phase)
The JAMA C++ library, which is an extension of TNT, was used to do SVD, matrix inversion, and eigenvalue decomposition
OpenGL and GLUT are used to create an interactive voxel viewer for the final 3D models
B. Hardware and Other Materials
A 60 minute Flip Video Camera is used to record the video footage of the object from different points of view. The camera has a 640x480 resolution. The idea is to see how well these algorithms could perform on a low budget camera such as this
A black posterboard and a black tablecloth serve as the backdrop for recording, to minimize background interference
A specially constructed calibration target is used (explained in the next section)
Data is taken in the following manner: one person holds the camera, while the other person holds the black posterboard in the background. The person with a camera encircles the object to be scanned on the table covered with a black tablecloth, and tries to keep the object and the calibration target in view. The person with the posterboard tries to stay in front of the person with the camera so that the black posterboard is always blocking out the background. This is all done in the Undergraduate EE labs, where lighting conditions are good.
Figure X: (Our Setup) Chris Tralie holds the camera while Chris Koscielny keeps the posterboard in the background
Before we can start reconstruction of the 3D models, we need to know some information about how the camera works and where it is positioned at each point in time with respect to the object we're trying to scan. One way to do this is to find a set of points in the image that correspond to known world coordinates. If we do this, we can create a camera model that can extrapolate and convert between any point in 3D world coordinates to the pixel locations in each camera (explained in section IV. Camera Calibration).
To automate the process of finding known points in the images from the camera, we decided to create a systematically colored cube as a calibration target (the "known points" reside on this cube). Here is a picture of the calibration cube below:
Figure X: Viewing our calibration cube from a certain angle
Figure X: The object to be scanned is placed on top of the calibration target as not to obstruct any of the checkerboard squares (obviously, this limits the size of the object that can be scanned)
The cube has five visible faces with part of a checkerboard pattern bordering around the perimeter of each face, with each square measuring 2cm x 2cm. Each face measures 16cm x 16cm. The background of each face is black, while the remaining colors of the 2cm x 2cm checkerboard squares on each face are Red (RGB = 100), Green (RGB = 010), Blue (RGB = 001), Cyan (RGB = 011), and Magenta (RGB = 101) (NOTE: these colors are chosen because they are all distinct and more easily identifiable under different lighting conditions than different shades of gray, etc). Each lateral face needs to have checker squares with a different one of these colors so that the faces can be uniquely identified; we need to tell the faces apart since we need to be able to circle the object from 360 degrees (we can't be mixing up the front with the back or the left with the right, etc).
Once the cube is constructed as such, we notice that each edge of the cube has a different pair of colors participating it. In the picture above, for example, the front-most edge going from top to bottom is composed of red and green checker squares (in addition to the black squares), and there are two different visible edge on the top that are composed of blue and red squares and blue and green squares, respectively. In other words, at the edges of the cube, there are corners created between the colored squares in each faces, and each corner has a very deliberate pair of colors to allow us to identify which edge we're looking at. Therefore, if we can accurately find all of the corners in the image, we can then look to see which colors the corner is composed of, and then use this information to decide if the color is on the calibration target and, if so, which edge it is a part of.
B. Automatically Finding Points on the Calibration Target
Using our calibration target, we have turned this 3D->2D point correspondence problem into a special type of corner detection problem. The goal is to find all of the corners in the image that are composed of (Black, Color1, and Color2), where Color1 and Color2 are a subset of (Red, Green, Blue, Cyan, and Magenta), depending on which edge of the cube the corner resides. The goal is to try to do as much of this as possible automatically, so that the user doesn't need to intervene to help the program nail these correspondences down. Here are the rough steps of the process:
Run a standard corner detection algorithm by looking at the eigenvalues of the gradient covariance matrix.
Take the output points and filter them by calculating an image descriptor in a neighborhood around each detected corner, then taking the squared Euclidean distance to precalculated descriptors and removing them if the distance is above a certain threshold. We compared three separate descriptors, all histogram based.
The first descriptor is just a histogram of the colors all points in the neighborhood.
The second descriptor is a histogram of the colors all points on the perimeter of the neighborhood. We tried this descriptor because we noticed that the image had color artificats near the corners of two colors, so we thought we might get better results if we ignore the pixels on the actual corner and look at the pixels around it instead.
The third descriptor is a histogram of the maximum number of neighboring same-color pixels around the perimeter of the neighborhood. This is a 5-dimensional histogram like the others, where each value represents a count of the maximum neighboring pixels of that color. We hypothesized that the additional information inherent in the descriptor would improve results.
After points are found along corners that are reasonable, RANSAC can be used to fit lines along edges of a particular type (since usually, there are a few outliers but lots of inliers). Lines for three different edges can be found this way, and they can be intersected to find a corner, which is a known 3D->2D point correspondence. Corner detection can then be re-done along each one of these lines, assuming that each new corner found is 2 cm away from the previous one along that principal direction. This is how we can fill in the rest of the known 3D->2D point correspondences (NOTE: This is currently unfinished).
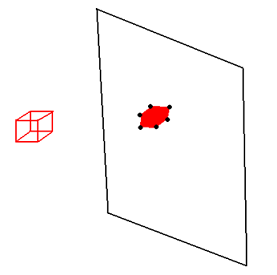
Figure X: An example running our RANSAC implementation on a synthetic point cluster with even more outliers than our data set normally has
C. Trial and Error: How We Got Here
The scheme described above is not the first scheme we came up with. It was only after tons of experimentation that we were able to come up with something that worked. The purpose of this section is to briefly outline some of the other things we tried, to show what doesn't work:
Originally, we tried to create a calibration target with 4 lateral faces, using white as the background and Red, Green, and Blue as the colors in the foreground
There were some serious problems with this approach, however. First of all, since white absorbs very little and reflects almost everything incident on it, we had issues with other colors "bleeding off" onto the white squares. So the white squares would often get confused as a different color. In addition, the lighting was far from uniform across the surface, so some regions of the cube were "in the dark." This meant that sometimes colors could be confused for black. Since black was one of the colors we were trying to find, this was a problem.
We drew two conclusions from this experiment:
We should not use white as one of the colors of the squares we're trying to detect under any circumstances
If we use black, we should have the light as uniform as possible (actually, the lighting should be uniform as much as possible regardless). We decided to head down to the undergraduate EE labs for the rest of our tests (which is very well-lit everywhere).
The next thing we tried was a calibration target with only the corners bordering on the edges on the cube (to minimize the potential for false positives on squares that don't even matter), and a different color scheme. Every face would have a yellow background (instead of white), and the five colors on the each face (4 lateral faces and the top face), out of Red, Green, Blue, Magenta, and Cyan.
The picture above shows the first scenario we tested it in. Unfortunately, the results were still abysmal. Not only did we miss most of the corners we were interested in, but we also picked up a ton of false positives in the background. We were ready to give up and try a different approach completely, but we still had a couple more ideas. We decided to create a controlled background and to have some sort of user intervention for selecting colors
In the next phase, we obtained a huge black posterboard to put in the background behind the calibration target. We also had the user select an example of Red, Green, Blue, Cyan, Magenta, and Yellow in the test images. As it turns out, however, this was not such a good idea. We started getting a lot of colors confused with green. Then, we looked around and noticed that in the EE labs, there's tons of green all over the place. Even though it's extremely well-lit, there's diffuse green light coming from all of the green glass panes bordering just about every wall. Since we can't control this and this type of situation can vary from location to location, we needed to come up with a more robust method to detect which corner is which color. This is when we decided to try to have the user select an example of a whole corner instead of just a color, and to create a histogram for the color distribution of the corners
In the next phase, we kept the same calibration target, but we instead had the user select examples of corners instead of colors. We then created a histogram for each corner type, where each pixel in some neighborhood of the user selected corner location was snapped to the nearest pixel out of (Red, Green, Blue, Cyan, Yellow, Magenta) in the histogram count. To check a corner type, a histogram would be compared via Euclidean Distance to the calculated histograms from user selection. The results significantly improved after doing this. Here is a screenshot of an initial test using this approach:
Note that most of the points are correct. There was a systematic problem telling the difference between red and magenta, however. I've circled in red a few places that this error surfaced. On the left, although every single green-magenta corner was found and nearly every magenta-cyan corner was found, they were all confused for green-red corners and red-cyan corners, respectively. On the image in the right, one of the cyan-red corners was confused for a cyan-magenta corner. Upon closer examination, we realized that the yellow was bleeding off into some of the other colors to make magenta. To fix this problem, we decided to change the background of each face to be black.
One additional problem that surfaced is circled in cyan. This is an example of a false positive in the background. Note that even though we switched to using a black posterboard in the background, there are still issues if any part of the background is not black. To fix this, we got a hold of a black tablecloth and put it on the table. After this, the only parts of the entire visible scene that aren't black are the squares on the faces of the calibration pattern and the object that's being scanned. This was the last little leap we needed to make this whole process acceptable for use.
Once at least 12 3D->2D point correspondences are known with reasonable accuracy (as determined in the previous step), a matrix model can be created to simulate what the camera is doing. That is, assuming a perspective camera model, a linear system can be created which projects points in world coordinates into the 2D viewing plane. This is a very important step in the pipeline, since later when we do space carving, we need to be able to check which voxels (approximately point locations in 3D space) project to which points on each image. If enough of the point projections agree in color (up to some confidence level), then we can say that 3D voxel actually does occupy space with that color.
The most general model for camera projection will allow for translation and rotation of world coordinates to align with camera before the points are converted from 3D to 2D. The only way to accomplish this with one matrix is to use homogenous coordinates. Therefore, assume the following matrix model (call the system matrix M):
=
where (X,Y,Z) is the 3D point in world coordinates, and the point (u, v) = (x/w, y/w) is the 2D point in pixel coordinates (NOTE: I will refer to the pixel coordinate as (u, v) for the rest of this section). This matrix M wraps every translation, projection, and rotation all up into one linear system. To solve for the 12 matrix entries, we will use at least 12 of the known 3D->2D point correspondences found in the previous section. The point pairs (X, Y, Z) and (u, v) are known from our correspondences, and we would like to solve for the matrix entries (a, b, c, d, e, f, g, h, i, j, k, l). We can begin by writing the following equations:
Multiplying (3) by u and v and substituting into (1) and (2), we get the following:
which leads to the matrix equation A*m = 0, with m = [a, b, c, d, e, f, g, h, i, j, k, l]T, and A
A
=
where N >= 12. If there are more point correspondences than 12, this is even better, since least squares techniques are being used to fit this model, and one would expect more point correspondences to give more information and, hence, a better estimate in most cases (so we use as many as we found in the previous step). More specifically, our system takes an SVD of the matrix A, and the solution to m is the column of the V matrix in the decomposition corresponding to the singular value closest to zero (since we were solving for A*m = 0).
NOTE ALSO: Technically the rank of the matrix A is 11, since there is an arbitrary scale factor over all of the parameters. But since the scale is uniform over the whole matrix, dividing by the "w coordinate" gets rid of the scale (so we don't have to worry about it).
B. Extracting Camera Parameters from the Fitted Projection Matrix
We're not quite finished even once we have the proper projection matrices for estimating what pixel location a 3D point maps to on each image. In addition to this, we also need to know the 3D position and orientation of the camera with respect to the origin in space. This is needed in the space carving step to determine which cameras can see which voxels (explained in the next section).
In order to estimate these parameters, we need to say a little bit more about what the camera is actually doing beyond the most general 3x4 projection matrix. Specifically, we will look at two classes of camera parameters: intrinsic parameters and extrinsic parameters. Intrinsic parameters are variables internal to the camera, such as focal length, that do not change from image to image. They describe how to convert a 3D point in camera coordinates to a 2D point in an image grid. Extrinsic parameters, on the other hand, tell how to convert a point from 3D world coordinates to 3D camera coordinates, so they include a rotation and translation system to accomplish this.
i. Intrinsic Parameters
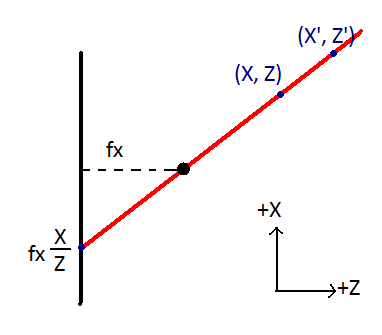
First take a look at the intrinsic parameters. The goal is to accomplish projection of a 3D point in camera coordinates to a 2D point on the image plane. In this project, we are assuming the strong perspective model for our camera, which says that all light rays coming into the camera are focused at a particular point in front of the image plane, which is a distance f (the focal length), in front of the image plane. Note that there are really two focal parameters, fx and fy, since the focal length for the x-axis and the focal length for the y-axis of the image are not necessarily the same. The following picture shows how to take this into consideration:
Figure X: The simple strong perspective projection model. Here fx is the focal length of rays projected along the x-axis. The point (X, Z) is mapped to position fx * (X / Z) on the image plane x-axis. Note how points (X, Z) and (X', Z') are mapped to the same point. This is a feature of the perspective model that makes variations in points farther away less noticeable
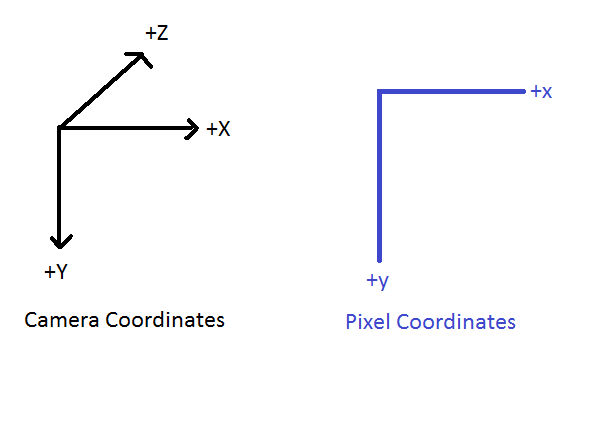
Note also that we need to be careful how we define the 3D camera coordinate system before we set up the matrix model. We chose to use the following right-handed coordinate system to be consistent with +Z moving points further away from the camera in the perspective model:
There's one more little quirk to take into consideration before the intrinsic projection can be completed. There may be a translational offset between projected points by the lens and pixel coordinates (u, v). This translation vector is called the image center, and it can be called (ox, oy). Summarizing what the entire system does in a matrix Mint:
Mint
=
Now a point in camera coordinates, Xc = [Xc, Yc, Zc]T, can be projected to pixel coordinates, xp = [xp, yp, wp]T, with the equation xp = Mint * Xc, and the pixels can be extracted by (u, v) = (xp / wp, yp / wp), where wp=Zc in this construction. In other words,
(u, v) = (fx * Y / Z + ox , fy * Y / Z + oy)
ii. Extrinsic Parameters
Now let's look at converting a point in world coordinates to a point in camera coordinates before any projection is done (these will be the parameters that we care about the most). We will need a 3x1 translational vector, T, and a 3x3 orthonormal rotation matrix R (entries denoted by rij), to accomplish this. Then they are simply composited next to each other in an affine matrix the usual way. Call it Mext (for "extrinsic matrix"):
Mext
=
A point in homogenous world coordinates, Xw = [xw, yw, zw, 1]T can be converted to camera coordinates, Xc = [xc, yc, zc]T, by the matrix equation Xc = Mext * Xw.
Note that R, the rotation matrix, is the upper left 3x3 sub-matrix of Mext. It is orthonormal, and each column corresponds to a basis vector of the original world coordinate system with respect to the camera's coordinate system. So, for example, if the camera is facing to the left, one of the columns of the R matrix will be pointing to the right.
The translation matrix, T, is the difference between the world origin and the camera center.
iii. Combining Intrinsic and Extrinsic Matrices, and Extracting Parameters from the Fitted Matrix M
The matrix M that we calculated in section (a) can be written as a product of the intrinsic and extrinsic matrices: M = Mint * Mext. Note that the extrinsic matrix is on the right since the translation and rotation from world coordinates to the camera coordinate system needs to be performed before the projection from camera coordinates to pixel coordinates. Expanding this product yields:
M
=
Mint * Mext
=
We now have to somehow match up the entries of this variable matrix with the entries of the matrix M we calculated in section a. The first thing to do is to note that M can be equal to the projection matrix up to a scale (since we normalized for scale in part a). To make sure it is the correct scale, we use the fact that the rotation matrix should be orthonormal, which means that in the bottom row of the expanded product above, r312 * r322 * r332 should be 1. So compute k = r312 * r322 * r332 and scale the entire matrix M down by k. Now the last row of the matrix should hold the correct values of (r31, r32, r33, and Tz), up to a sign (explained later).
The next step is to calculate the image center, (ox, oy). Once again, we exploit the fact that R should be orthonormal, and we take the dot product (m11, m12, m13) * (m31, m32, m33):
since the first row of R dotted with the third row of R is 0, and the third row of R dotted with itself is 1 (due to the fact that R is orthonormal). So ox is (m11, m12, m13) * (m31, m32, m33) (after M has been scaled down). By a similar argument, oy = (m21, m22, m23) * (m31, m32, m33)
Next we will attempt to solve for the focal parameters, fx and fy. Start by taking the dot product of (r11, r12, r13) with itself. We get:
which is fx2 + ox2 (by the same orthonormal arguments above, i.e. taking a row of R dotted with itself is 1, and dotting two different rows is 0). So to extract fx, take the dot product of (r11, r12, r13) with itself, subtract ox2, and take the square root.
To get fy, do the same thing with row 2 and subtract oy2.
Now solving for the rest of the parameters is easy
TODO: Explain choosing a correct sign (but I'm not even going to start doing that until the magnitudes of the translation vector look right)
C. A Note About Accuracy of the Camera Projection Matrix
During experimentation, it was found that using more than 12 points is a definite plus. In fact, because of noise, using any fewer than 16 in general does not give good enough coverage for the projection matrix to be of any use beyond the calibration target in the image. Also, the point correspondences should not be biased too much to one face (or plane) of the calibration target. If the camera calibration is performed using too many points on the same face, then the projection will be extremely accurate on the plane of that face, but on any other plane it will begin to fail beyond acceptable tolerance levels that the voxel coloring algorithm needs (up to +-3 cm error in projection was seen only 8 cm from the origin on a different plane in one testing scenario). Dividing up the points evenly between at least two different faces of the calibration target seems to fix this.
Once projection of 3D world coordinates to 2D pixel coordinates is possible for every viewpoint, we can begin to do 3D reconstruction using a technique known as "voxel coloring." The basic idea is very similar to carving a sculpture. We start with a regular 3D array of "voxels" (the 3D analog of a pixel), which are fixed to a particular size, can each have an RGB color, and are either occupied or not. We then go through each voxel and project it to the image of every camera that can see that voxel. We check to see if the cameras agree on which color the voxel is. If the cameras agree on the color beyond a certain standard deviation, then we assume that there actually is a solid at that location with that particular color, so we "color" the voxel with the average of all colors seen from the different cameras. If the standard deviation is too high, however, then we "carve" the voxel; that is, we assume that since the cameras don't agree about what was seen, that 3D location must not actually be occupied by anything, so the voxel that resides there is removed.
The basic algorithm is in place, but with a few important details missing. First of all, how do we determine which cameras are able to see a particular voxel? Because of the perspective camera model, there are many voxels that can lie along a particular line of sight and will get projected to the same point on a particular image, yet only the first one will be seen (it will occlude all of the voxels behind it). So we need to determine which voxels will be occluded, and not consider the opinion of the cameras that are occluded when looking at such voxels. One approach to this problem is to use something called plane sweep space carving..
Figure X: Plane Sweep Space Carving (Picture courtesy of Kutulakos and Seitz [2]
The idea is to come up with a scheme that visits occluders before occludees, so that a particular camera knows not to consider pixels if they have already been used to color something (since that something would be an occluder). More specifically, the algorithm starts at the front of the slab of voxels, fixes one coordinate (in our case, the plane is swept down the Z-Axis), and looks at all of the voxels on the plane defined as such. Only the cameras that are in front of the plane are considered (colored in orange in the above figure), since cameras at the back are potentially occluded by voxels that haven't been colored yet (the gray part of the slab in the above picture behind the plane). After this process has been done for a single plane, increment the index of the plane and move to the next one, until the entire voxel structure has been traversed.
One more step that needs to be taken is the "masking" of pixels that have already considered. As previously mentioned, if a pixel in a camera has already been used to color a voxel, and since occluders are visited before occludees, the pixel should not be used again to vote on the consistency of a voxel from different camera viewpoints (since this particular voxel will be occluded by the one that was previously colored). The way to keep track of which pixels have already participated in a consistency check is to create a mask of booleans behind all of the pixels, and to set an element of that mask to "true" when the pixel has participated in a consistency check that has passed and led to the coloring of a voxel. Another point to note is that a cubic voxel projects to a hexagon on the viewing plane of the camera [1]. Therefore, when doing the consistency checks and creating a mask, we should consider all pixels within the bounding box of this hexagon projection:
Figure X: A voxel projects to a hexagon in an image
One last thing to note is that RANSAC can be used to help correct for errors in this process. Since we were having a difficult time extracting the extrinsic parameters, such as the translational offset, it was difficult for us to say exactly which cameras were in front of the current scan plane. The masking will still work, but we had to include all of the cameras that aren't masked just to make sure we didn't miss any (which leads to some incorrect viewpoints being considered, especially towards the beginning). To try to cut out the incorrect cameras, RANSAC is used on the colors of all pixels considered, and the consistency check for a voxel is passed if RANSAC finds a model with at least 50% of the considered pixels colored below a chosen standard deviation.
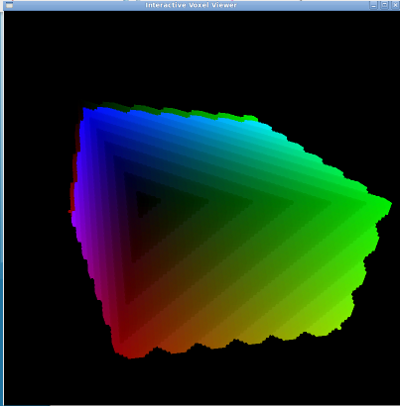
We created a simple interactive voxel viewer using OpenGL and GLUT starting from the code in the triangle mesh viewer in assignment #2 from computer graphics last spring. The voxels are saved in binary format (VoxelCloud.cpp implements this), and this viewer can load them. The viewer loops through and draws each voxel as a colored 6-faced cube. Upon initialization, the program automatically zooms to have the object in full view. To rotate the object around its center, hold down the left mouse button and drag. To zoom in and zoom out, hold down the middle mouse button and drag. To translate the object, hold down the right mouse button and drag. Here is a screenshot of this program in action:
Unfortunately, the program is not fully working at this point, and due to time constraints, it will be left incomplete for now (we were too ambitious for a mere final project...this is enough work to have been an independent work project). There are two main problems. First of all, the automatic 3D->2D point correspondence finder is not yet reliable enough to be used in real scenarios (though it is close). Secondly, the camera calibration is not reliable enough to be used to do the voxel coloring step. The error is a bit to much for the consistency checks to work, and the translation vector is not reliable enough to discount cameras (as mentioned in the voxel coloring section. But this is also close to working. Therefore, we will present some isolated results at different points of the pipeline
A. Results from Automatic 3D->2D Point Correspondence Finder
Before carrying out the following tests, we selected 4 points of each type around the cube (on images where the camera pointed directly at a corner) and found the average histogram for each type using the program. The points we used are saved as sm_points (points for smallworld.avi with step_size 10). We first examined an image of one corner, then compared results using the 3 different descriptors with different parameter values. We found that the basic perimeter histogram descriptor performs the best, so we examined it's performance around other corners. For all the images below, note the following code:
Type 0 - green-cyan corner - red box
Type 1 - magenta-cyan corner - white box
Type 2 - blue-cyan corner - magenta box
Type 3 - red-cyan corner - blue box
Type 4 - red-green corner - cyan box
Type 5 - red-blue corner - green box
Type 6 - magenta-green corner - gray box
Type 7 - magenta-blue corner - black box
Basic Histogram Descriptor on Red, Green, Cyan Corner
We tried increasing the neighborhood width to 8 and it drastically slowed down performance because it needs to calculate much larger histograms (also note how we had to significantly increase the hist_threshold to compensate). However, as the image below shows, the results also improved (numerous false corners were removed).
Increasing the neighborhood width to 8 also improved performance on the perimeter descriptor. Increasing the width didn't have nearly as severe an impact on the speed because not as many histogram points are added per increase in width.
The perimeter neighbors descriptor performed reasonably well, but it tended to confused red with magenta (based on the few gray squares on the red-green corners). This descriptor should be further examined with the calibration target proposed in the summary below.
Basic Perimeter Histogram Descriptor at different angles
These results show that the algorithm still performs well with the same parameter values as above when the camera is rotated slightly. However, the algorithm has trouble detecting corners when the camera is rotated too far. Perhaps this issue could be resolved by taking separate histograms for corners that appear at sharp angles relative to the camera.
Basic Perimeter Histogram Descriptor on different corners
We used the same parameters as above to achieve these somewhat disappointing results. These three images reveal that the algorithm has serious trouble distinguishing red and magenta. However, this is understandable considering we sometimes had trouble distinguishing the colors in the pictures.
B. Camera Calibration Results
Here is a basic test scenario where the camera is calibrated "by hand" (i.e. bypassing the previous step and picking out the 3D->2D point correspondences manually in "The Gimp"). Here a picture of Einstein on top of the calibration target is taken, and we attempt to locate his left foot, left hand, and moustache. Here are the results (a white dot indicates the program's guess as to where a 3D point projects to the image, and we circled it in red to help show where it is):
Original Image
Looking for Einstein's left foot (x, y, z) = (6cm, 0cm, 6cm) NOTE: "Up" in the Y direction is negative to keep consistent with the right-handed coordinate system defined earlier
Looking for Einstein's left hand (6cm, -5cm, 6cm)
Looking for Einstein's moustache (8cm, -11.5cm, 7cm)
When taking into consideration measurement error, these results aren't too bad.
C. Voxel Coloring Results
This test was performed using 10 still images of the Einstein action figure that were calibrated "by hand."
Test 1: 24x24x24 voxels, each 0.5 cm (spanning a total volume of 12cm x 12cm x 12cm on top of the calibration target), capping the standard deviation at 22 for the consistency checks
Command: ./main manual 0 0 0 24 24 24 0.5 22
Test 2: 12x12x12 voxels, each 1 cm (spanning a total volume of 12cm x 12cm x 12cm on top of the calibration target), capping the standard deviation at 30 for the consistency checks
This project ended up being much more difficult than we expected, but we were at least able to make progress on each individual portion of the pipeline. First of all, we spent a lot of time figuring out what does and doesn't work with finding known points on the calibration target, and we are close to getting that part of the pipeline to work. Here are some more observations about that part of the pipeline:
Increasing the gaussian width greater than 2 usually led to poor results. Some points (e.g. the red-cyan corners tended not to show up when the blurring was too great).
Increasing the eigenvalue threshold (ET) tends to speed up the algorithm because it reduces the number of points that need to be examined in later more computational steps. Increasing the eigenvalue threshold also tends to improve the results by removing points that are less likely to actually be corners of any type. However, making the threshold too high will filter out desired points.
Lower histogram threshold values are needed for perimeter-based descriptors because these histograms have far few points hence much lower squared euclidean distances.
In all descriptors, lowering the histogram threshold helped remove false positives and often helped the algorithm choose correctly between 2 similar colored corners (e.g. red-blue and magenta-blue corners).
Increasing the neighborhood width for the descriptors tends to improve the performance of all descriptors. Intuitively, it makes sense that examining more information around each corner will allow us to better identify the corners we're looking for. Unfortunately, increasing the width for the simple histogram drastically increases the number of points per histogram and significantly slows down the algorithm.
The algorithm still has trouble distinguishing between similar colors (e.g. red and magenta). If we had time to further revise our calibration target, we could make the top blue, and make sides alternate with red and green (with a black background). We hypothesize that we would get significantly better results on such a target (i.e. we would get results better than the perimeter histogram for the red, green, and cyan corner on every corner). Although the colors on the corners would no longer precisely identify the corner type, we could distinguish between the various corners based on the current frame's position in the video (i.e we utilize the fact that the camera will always be rotating in a single direction).
If we had more time, we would investigate automatic tuning of parameters. Based on the results, it seems like we would only need to tune once (assuming we used the new target proposed above). However, multiple tunings could be required depending on how complex the object to be scanned is from different directions; the consistency of the background throughout the video also may determine whether or not the parameters need to be tuned multiple times.
Next is the camera calibration part of the pipeline. As can be seen in the results, the 3D->2D point projection from world coordinates to pixel coordinates was pretty good, but not good enough to make the voxel coloring portion of the pipeline accurate enough. with the consistency check. Perhaps the linear projection model is too much of a simplifying assumption in this case. Perhaps a first or second order radial distortion model would have helped (the points are just off enough that it makes us suspicious that this may be our issue). If we were to take this approach, we would try to find straight lines in the image and warp the image such that they actually were straight, and then apply the linear model.
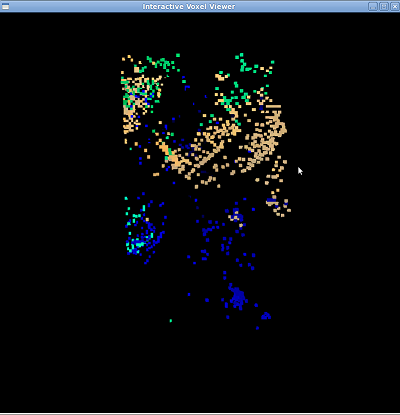
Last is the voxel coloring part of the program. This is one of the most disappointing of all, but there are a few things that went right. First of all, notice that the color distribution is at least partially correct. Voxels that are skin colored appear closer to the top of the image where the head is, and blue voxels appear towards the jean-colored pants. Also during testing, increasing the standard deviation definitely colored more voxels. Because of time constraints, we didn't have time to do much more testing (also each test run takes about 5+ minutes depending on the resolution of the voxels), but we suspect that tuning the parameters perfectly would help the results a lot. The testing process will be accelerated greatly once the 3D->2D point correspondences section has been sped up (right now it takes about an hour to do 10 images by hand).
One last thing that might help would be doing plane sweeping in the other directions as described in the paper on space carving [2]. To do this effectively, we would really need to nail down our extrinsic parameters, which would require improving camera calibration as described before.
Found the CImage Library for C++ [7], and figured out how to use it for both image processing techniques and user interaction
Implemented corner detection techniques in C++ using the CImage library
Experimented with finding known 3D->2D point correspondences using corner detection, and made many iterations to the design of this part of the pipeline
Created a user interface to allow the user to select an example of each different type of corner on the calibration target, and came up with different descriptors for each corner to try to estimate the type in a noisy image as effectively as possible
Helped to resolve linking issues and to integrate all aspects of the program smoothly
Chris Tralie
Created a program to automatically make a calibration target of a given size suitable for printing on a color printer
Added functions on top of the TNT Matrix library to make it more usable
Implemented RANSAC for line-fitting and color model estimation. RANSAC is in a position to be used with repeated corner detection to finish the 3D->2D part of the point correspondences pipeline (but is unfinished)
Implemented linear perspective camera calibration and programs to interactively test the model
Implemented plane sweep space carving techniques to do voxel coloring
Created an interactive voxel viewer in OpenGL for viewing results
A file that automatically generates the checkerboard border patterns for the faces of the calibration target using the CImage library. This program allows the user to adjust the size of the squares in the calibration target, using a conversion factor between centimeters and pixels [4]
Camera.cpp, Camera.h
The main class for storing all of the information in the "camera" associated with one image. This includes the image taken by the camera (stored as a CImage object), the projection matrix for projecting 3D world coordinates to the pixel coordinates of this viewpoint, the translation vector for helping to orient the camera, and the mask for helping with the voxel coloring stage.
cimg_test/correspondence_detection.cpp
The main file that does automatic corner detection for the 3D->2D point correspondences, with the help of a user interface for picking out different corner type examples
main.cpp
Right now, this program initiates voxel coloring with cameras with point correspondences manually picked out
Makefile
A makefile for automatically building each part of our program and for linking in the GLUT, TNT, and CImg libraries
Ransac.cpp, Ransac.h
An implemenation of the RANdom SAmple Consensus algorithm to find a best fit for lines and for colors, given a cluster of points in the former case and a cluster of pixel colors in the second case. This method is robust to outliers
TestProjection.cpp
Given an image and a set of 3D->2D point correspondences, this program tests the camera calibration matrix. It allows the user to specify a 3D point, and it draws a small white square over the pixels on the image that correspond to that 3D point in space
TNT_Utils.cpp, TNT_Utils.h
A few extra features to make the TNT library more usable. This includes matrix multiplication, transposition, and inversion functions for "2DArray" objects. It also includes a least-squares solver using these utilities.
Voxel.cpp, Voxel.h
Stores a Voxel with a color and a flag to indicate whether or not it has been carved. Note that by default, all of the voxels in the cube start out in place (occupied = true), and they are only carved if they fail the consistency test
VoxelCloud.cpp, VoxelCloud.h
Stores a cube of voxels and provides functions to easily access voxels at a particular (x, y, z) coordinate. Provides binary functions for reading and writing these structures to a file. NOTE that this is the main class for storing the 3D object results
This program was developed and tested under Ubuntu Linux 9.10. The following packages should be installed before running this:
freeglut3
freeglut3-dev
cimg-dev (1.2.0.1-2.1)
libtnt-dev
libjama-dev
ffmpeg
B. Running the automatic 3D->2D Correspondence Detection Program
The correspondence detection program contains our automatic correspondence detection algorithm for the cube and a GUI to test and analyze it. We were originally planning on moving the code into a separate module to connect into the voxel coloring pipeline, but since we couldn't get the final step of the process working using hand-chosen data, there wasn't much point connecting everything. Therefore, correspondence_detection is a standalone program. Note: you must have ffmpeg installed in order to break the video into frames.
Tutorial for using the program
Open a terminal window and run:
./correspondence_detection -h
- this will display a list of parameters that you can change to affect the performance of the correspondence detection.
Make sure smallworld.avi is located in your directory, then run:
./correspondence_detection -i "smallworld.avi" -fs 10
Note: make sure you run the program from a terminal window.
The program will start by breaking "smallworld.avi" into frames and saving them in a directory called "frames". It will then load every 10th frame into memory.
After the frames load, you will be presented with 2 windows, one big window with the first frame of video, and one very small frame that displays the pixels around the neighborhood of your cursor. This small window will be very useful for when you need to select corners precisely. You can change frames by clicking the title bar of the big window and pressing left and right arrows (make sure not to actually click the image, because that will add a corner point). You can see debug output in the terminal window you used to start the program.
Click a corner on the colored box in the image in the main window. You should get the following output in your terminal window:
"Added new corner of type 0 | hist # 1"
With the main window selected, press t and list of corner types and corresponding colors will output in the terminal window. The second line of output says:
"Type 1 - magenta-cyan corner - white box"
This means that the magenta and cyan corners (with black background) are type 1 and that they will be indicated with a white box when the program searches for the corners. Make sure the main window is selected and press 1.
"Changed corner type to 1"
will output in the terminal window. This means that when you next click the image, the neighborhood around where you click will be stored as an example of a magenta-cyan corner (type 1). When you start the program, you default to type 0, but, with the main window in focus, you can press any number 0-7 to change the current type (I.e. the next point you click should be a corner of that type).
Select 3 points of type 4 (red-green) and select 3 points of type 5 (red-blue) – you may need to use the arrow keys to view different frames of the video with the desired points. Make sure the main window is in focus and press p – this will output the current list of selected points. Make sure the main window is in focus and press s. Now, click the terminal window and enter a file name to save your points and press enter.
Close the program and restart it. Now, with the main window selected, press l, and then enter the name of the file you just saved and press enter. Now, selected the main window again and press p to view the points you just loaded. Press l again and load "sm_points", a set of pre-selected points for small_world.avi (note: make sure you run the program with -fs 10). Press p and you'll see that there are 4 points for each type of corner.
Make sure the main window is in focus and press q to leave the interface for selecting points. Another window will pop up with the same image that was displayed when you pressed q.
With the main window in focus, press a to calculate the basic histograms around each point that was loaded. Press z to average the histograms of the same time. Finally, press the up arrow to calculate the
correspondence points. The list of parameters being used will output to the terminal window; a single character is listed to the left of each parameter in parentheses. You can change that parameter by pressing that key with the main window selected, then entering the new parameter in the terminal window.
If you want to try a different descriptor, you must reload the points by pressing l. 'b' will tell the program to use the basic perimeter descriptor and 'c' will tell the program to use the perimeter neighbor descriptor. Remember to press z before running the program, or each corner will be compared to each of the four points per corner type (though this might be desired).
C. Running the Voxel Coloring Program
To run the voxel coloring program on a manual data set, use the "main program" with the following syntax:
./main [directory] [start_x] [start_y] [start_z] [numvoxels_x] [numvoxels_y] [numvoxels_z] [resolution of voxel] [max standard deviation for consistency check]
Right now, the directory must hold jpeg images, each called "frameX.jpg", where X starts at 1, and each frame should have a corresponding 3D->2D point correspondences text file (so that they can be manually specified) called "correspX.txt." Right now, a test data set has been provided in the directory called "manual," and this is the set that was used in the "Results" section
Kiriakos N. Kutulakos and Steven M. Seitz. A theory of shape by space carving. In International
Journal of Computer Vision, 38(3): pages 198-218, 2000.
Koen van de Sande and Rein van de Boomgaard. 3D Reconstruction using Voxel Coloring. University of Amsterdam. October 9, 2004.
Steven M. Seitz and Charles R. Dyer. Photorealistic scene reconstruction by voxel coloring.
In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 1067-
1073, 1997.







![\[ \left( \begin{array}{cccc}
a & b & c & d \\
e & f & g & h \\
i & j & k & l \end{array} \right)\]](latex0.png)
![\[ \left( \begin{array}{c}
X \\
Y \\
Z \\
1 \end{array} \right)\]](latex1.png)
![\[ \left( \begin{array}{c}
x \\
y \\
w \end{array} \right)\]](latex2.png)
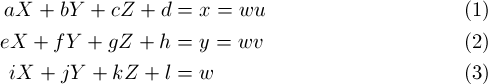
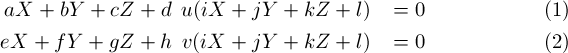
![\[ \left( \begin{array}{cccccccccccc}
X_1 & Y_1 & Z_1 & 1 & 0 & 0 & 0 & 0 & -u_1X_1 & -u_1Y_1 & -u_1Z_1 & -u_1 \\
0 & 0 & 0 & 0 & X_1 & Y_1 & Z_1 & 1 & -v_1X_1 & -v_1Y_1 & -v_1Z_1 & -v_1 \\
X_2 & Y_2 & Z_2 & 1 & 0 & 0 & 0 & 0 & -u_2X_2 & -u_2Y_2 & -u_2Z_2 & -u_2 \\
0 & 0 & 0 & 0 & X_2 & Y_2 & Z_2 & 1 & -v_2X_2 & -v_2Y_2 & -v_2Z_2 & -v_2 \\
. &. &. &. &. &. &. &. &. &. &. &. \\
. &. &. &. &. &. &. &. &. &. &. &. \\
X_N & Y_N & Z_N & 1 & 0 & 0 & 0 & 0 & -u_NX_N & -u_NY_N & -u_NZ_N & -u_N \\
0 & 0 & 0 & 0 & X_N & Y_N & Z_N & 1 & -v_1X_N & -v_1Y_N & -v_1Z_N & -v_N \\
\end{array} \right)\]](latex5.png)
![\[ \left( \begin{array}{ccc}
f_x & 0 & o_x \\
0 & f_y & o_y \\
0 & 0 & 1 \end{array} \right)\]](latex6.png)
![\[ \left( \begin{array}{cccc}
r_{11} & r_{12} & r_{13} & T_x \\
r_{21} & r_{22} & r_{23} & T_y \\
r_{31} & r_{32} & r_{33} & T_z \end{array} \right)\]](latex7.png)
![\[ \left( \begin{array}{cccc}
f_xr_{11} + o_xr_{31} & f_xr_{12} + o_xr_{32} & f_xr_{13} + o_xr_{33} & f_xT_x + o_xT_z \\
f_yr_{21} + o_yr_{31} & f_yr_{22} + o_yr_{32} & f_yr_{23} + o_yr_{33} & f_yT_y + o_yT_z \\
r_{31} & r_{32} & r_{33} & T_z \end{array} \right)\]](latex8.png)
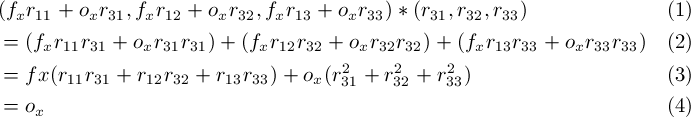
![\[ f_x^2(r_{11}^2 + r_{12}^2 + r_{13}^2) + 2f_xo_x(r_{11}r_{31} + r_{12}r_{32} + r_{13}r_{33}) + o_x^2(r_{31}^2 + r_{32}^2 + r_{33}^2) \]](latex10.png)